Why GPUs, Not CPUs, Are Essential for Running AI

Today, it's undeniable that Artificial Intelligence (AI) has become a ubiquitous topic, playing a pivotal role across industries. With its ability to analyze and process vast amounts of data, delivering user-desired outputs within seconds, AI truly represents the new wave of technological advancement.
Beyond leading AI creators like OpenAI (ChatGPT), Google (Gemini), and Microsoft (Copilot), a crucial, indispensable component for running and processing AI is the underlying hardware. In the AI era, one company has emerged almost unrivaled in this domain: NVIDIA, the renowned graphics card manufacturer well-known to gamers.
So, why has a graphics card manufacturer become the leader in AI hardware in this era?
The answer lies with the GPU, or Graphics Processing Unit, which is the graphics processing chip found on those very graphics cards.
But why does AI necessitate using a GPU, rather than the CPU, which we are accustomed to as the primary processing unit?
The answer lies in the processing patterns. Although both GPU and CPU are processing units, their underlying processing methodologies differ significantly. To grasp this, let's first understand the core power of CPUs and GPUs to comprehend the main distinctions between these two crucial processing units.
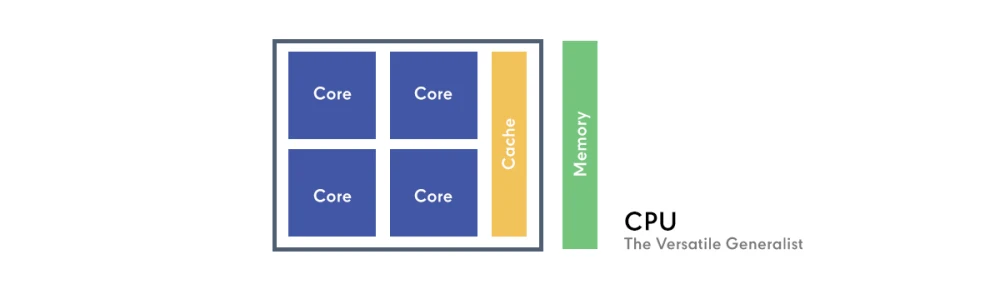
CPU: The Versatile Generalist
The CPU is engineered for immense versatility. It excels in sequential processing, handling complex tasks one after another with high speed and precision. Imagine a CPU as a highly intelligent manager capable of tackling a wide array of intricate problems, focusing intensely on each task from start to finish. Typically, a CPU features a few powerful cores optimized for complex decision-making and diverse workloads, making it ideal for operating systems, word processing, web Browse, and general application execution.
GPU: The Parallel Specialist
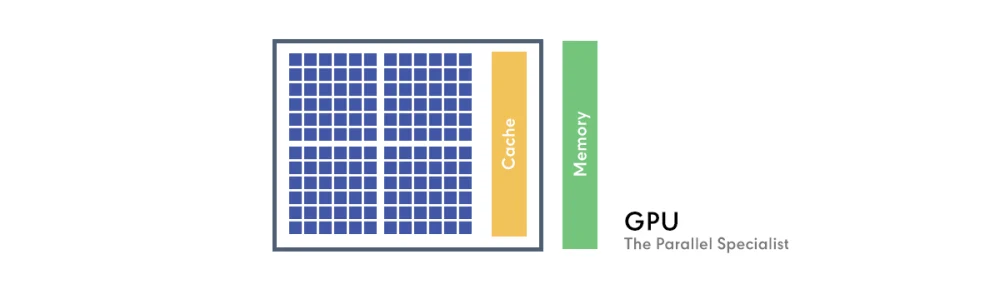
Conversely, the GPU was originally designed for graphics processing, which involves performing millions of similar calculations simultaneously (such as processing individual pixels on a screen). To achieve this, a GPU comprises thousands of smaller, highly specialized cores. Envision a GPU as a vast team of highly efficient workers, each capable of performing simple, repetitive tasks very quickly, all at the same time. While they might not possess the same "intelligence" as a CPU's manager, their collective parallel processing power is unmatched for specific types of workloads.
It is precisely the distinct parallel processing nature of the GPU that makes it exceptionally suited for specialized tasks like Machine Learning and Deep Learning. The operations within Artificial Intelligence, especially in Deep Learning models or Neural Networks, are fundamentally based on simple yet massively repetitive mathematical computations.
The nature of the CPU, however, is fundamentally different. CPUs excel at juggling diverse and complex tasks (e.g., running multiple programs, processing documents, managing operating systems) by utilizing a few highly intelligent cores that switch between tasks. However, if a CPU were used to process AI workloads that demand millions of repetitive calculations, it would quickly become a severe bottleneck. This is because it's designed to execute tasks meticulously, step-by-step, not to distribute a massive volume of identical operations across many parallel units simultaneously.
For AI that demands massive data processing in a highly repetitive and parallel fashion, the GPU presents a perfectly suited architecture. It can perform "simple, repetitive tasks simultaneously" many times faster than a CPU, drastically reducing the training time for large and complex AI models from days to mere hours. This makes the GPU an indispensable powerhouse in the world of modern Artificial Intelligence.
It is precisely this immense demand from AI that propelled NVIDIA, a long-standing GPU manufacturer, to instantly become a leader in AI hardware. The company experienced exponential growth as NVIDIA GPUs became highly sought after.
Since AI requires GPUs, why aren't AMD's Radeon GPUs as sought after?
The answer lies in what is known as CUDA

CUDA is a proprietary parallel computing platform and API (Application Programming Interface) that enables developers to easily and efficiently program NVIDIA GPUs to harness their parallel processing power.
Thanks to NVIDIA's long-term development of CUDA, a vast community of developers utilizes it. Popular AI libraries and frameworks like TensorFlow and PyTorch are primarily built and optimized to perform best on CUDA and NVIDIA GPUs. This has created a very strong "Network Effect" or "Lock-in Effect" in the AI development ecosystem.
While AMD has recently caught up to its long-time rival Intel in other areas, its AI ecosystem, known as ROCm (Radeon Open Compute platform), has been slower to mature and grow compared to CUDA. This results in a smaller developer community, less comprehensive libraries, and a non-trivial challenge for developers to migrate projects from CUDA to ROCm.
Furthermore, NVIDIA's commitment extends beyond just powerful graphics processing. They have heavily invested in designing specialized AI hardware, notably Tensor Cores. These dedicated processing cores are engineered to accelerate matrix computations, which are at the heart of Deep Learning. This significantly speeds up AI model training. NVIDIA also widely adopts High Bandwidth Memory (HBM) in its Data Center GPUs, crucial for rapidly feeding immense amounts of data to AI cores. AMD, in contrast, currently lacks comparable hardware or efficiency to NVIDIA's Tensor Cores in the AI market, further solidifying NVIDIA's position as an unrivaled leader in AI hardware in this era.